「与西北大学(NU) MLL Lab 博士生王子涵“逛”开源。」
(题图:开源大模型推理框架 vLLM 的 GitHub 页面截图,该项目已有 800 多社区贡献者。)
上周五,DeepSeek 在官方 twitter 上预告了下一周会连续 5 天开源 5 个代码库,进入 open-source week,开源周。
我们录制节目的这天是周一,DeepSeek 也正式放出了开源周的第一个开源项目 FlashMLA。

我一直很想和人好好聊一下,大模型开源是在开什么,怎么开。比如相比闭源模型,开源要额外做一些什么工作,才能让社区比较好地理解到这个开源成果,以及能更充分地把开源用起来。
正好在 DeepSeek 这个开源周,我邀请到了正在美国西北大学 MLL lab 攻读博士学位的王子涵。
子涵今年刚博一,之前毕业于人大,大四时,也就是 2024 年,他曾在 DeepSeek 实习半年,今年暑假即将前往一家美国 AI Agent 从创业公司,Yutori 实习。
随着 DeepSeek 在春节的爆火出圈,开源也正成为一种趋势:之前一直模型闭源的一些公司,如 MiniMax、阶跃星辰,从 1 月到现在都陆续发布了自己的第一批开源模型。
之前选择保留自己最强模型闭源,开源较小版本模型的公司,可能也会在 DeepSeek 的冲击波里有新选择。
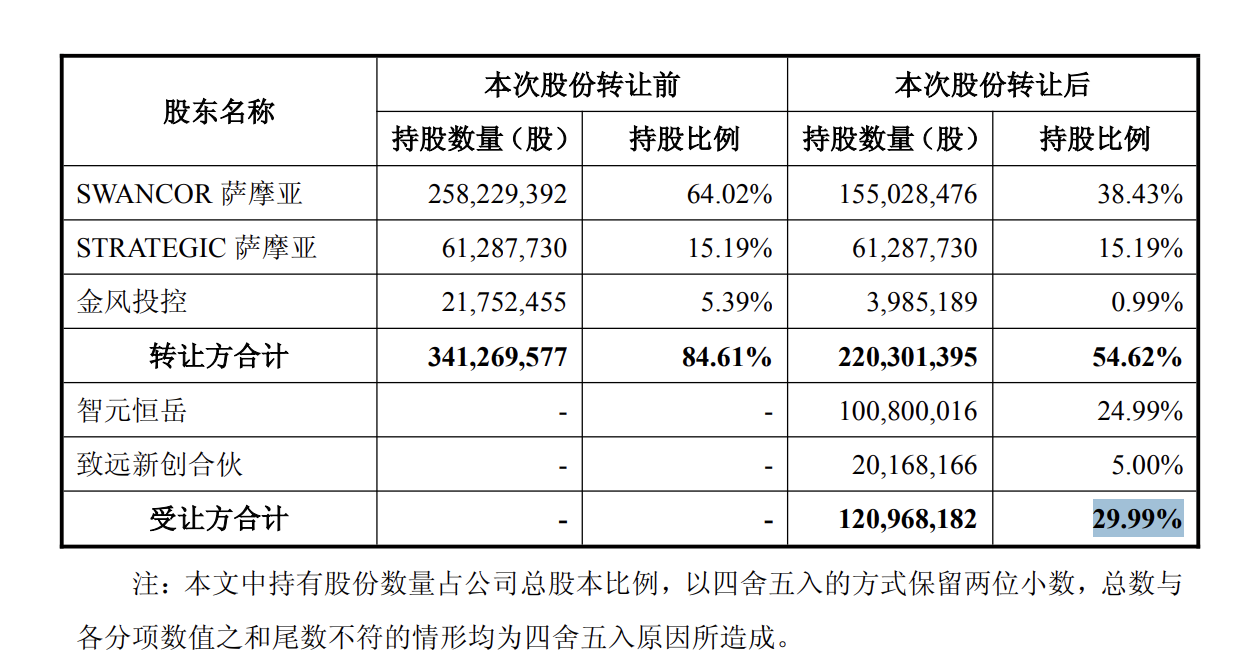
这期我和子涵聊到了开源模型不同的层级,主要有技术报告,模型权重,推理框架,训练框架,还有数据集。现在我们说一个模型是开源的,一般指的是有技术报告也开放了模型权重。再往下更深入的开源,是推理框架和训练框架。而现在只有极少数的机构,比如 Allen AI 研究所,他们也开放过预训练的数据集。
我们也在一起围观 DeepSeek 开源周的过程中,回顾了他们之前开源模型的一些重点优化思路,以及他们为了让社区充分理解和使用开源成果,而专门花费心力去规范代码,写详细的技术报告。这背后是一个组织对优先级的选择。
而在本期最后,子涵也分享了一个自己成为开源模型滥用“受害者”的亲身经历。开源在加速技术进化,如 DeepSeek 开源周 twitter 预告里所写:acclerates the journey;也带来一些隐患,需要整个领域一边开源,一边探索解决。
马斯克曾经说:“有人问我是不是想死在火星上,我说当然,但不是死于(登陆器降落时的)撞击。”
登场人物:
嘉宾:王子涵,西北大学 MLL Lab 博士生 (个人主页 https://zihanwang314.github.io)
主播:程曼祺,《晚点 LatePost》科技报道负责人
剪辑制作:甜食
本期节目中提及的一些开源项目的 GitHub 页面:
DeepSeek:https://github.com/deepseek-ai
DeepSeek/Open-Infra-Indes:https://github.com/deepseek-ai/open-infra-index
DeepSeek/FlashMLA:https://github.com/deepseek-ai/FlashMLA
vLLM:https://github.com/vllm-project/vllm
SGLang:https://github.com/sgl-project/sglang
字节跳动/Verl:https://github.com/volcengine/verl
DeepSeek/ESFT:https://github.com/deepseek-ai/ESFT
本期节目涉及一些AI 项目、机构,见 shownotes 末尾附录。
时间线跳转:
-DeepSeek 开源周指向 Infra,已放出第一个库 FlashMLA
02:20 过往实习、工作中的开源项目
03:18 王子涵分享自己开源工作,包括在数研时做的 agent 相关 benchmark,以及参与 DPCVR 研发和关于 DPCRY 加 agent 的开源报告。
05:17 DeepSeek 开源周预告,强调 Small but sincere;第一个库已发布:FlashMLA;未来开源方向推测
09:30 FlashMLA,一个用 C++ 语言写到算子层的推理框架优化;像 DeepSeek 这样做大量更底层算子优化的努力比较难
17:14 FlashMLA GitHub 反馈(issues)速览:有人想要 FP8,有人问何时支持 NPU?
-一起来逛 GitHub 库,大模型开源是在开什么
19:23 一起逛 GitHub 仓库(Repo),在开源项目里该看什么?
·看 license(开源协议),DeepSeek 惯常使用的 MIT 协议,开放、简洁、免责
·看 readme,树状学习库的基本信息,需要的环境、如何部署
·子涵更喜欢看 issues,而不是 star,issue 反映多少人在深度玩这个库;PR(Pull Requests)是更深度的代码贡献。
31:30 大模型开源到底在开什么:技术报告、模型权重、推理框架、训练框架、数据集。一般一个开源模型都有技术报告和权重,但推理和训练框架的代码和数据集则不一定,尤其是数据集。
35:23 vLLM、SGLang,两个活跃的开源推理库;模型权重的下载途径;字节其实开源过一般较少开源的训练框架 (Verl)
41:25 数据开源几乎没有,主要是出于信息敏感性和安全性考虑。
42:38 除了数据集,DeepSeek 已开源过上述各部分,其中子涵参与的 ESFT 工作就也开源了训练框架。
44:16 从闭源到开源,需要 another layer of hard work:如规范代码、适配开源推理或训练框架。
-不同的开源策略:开源最强模型 VS 有所保留
49:14 不同开源策略主要和盈利模式与诉求有关。不靠 API 赚钱或期望推动更大格局变化(如形成标准)可能选择开源最强模型;另外,一些非盈利机构也会“非常开”,如 Allen AI 和 EleutherAI,罕见地开源了数据集。
51:29 是否会看到 OpenAI 开源最强模型?不确定。Sam Altman 在 twitter 发起投票的两个开源选项(o3-mini 和 phone-sized model)都值得期待。
52:36 子涵分享一个大模型滥用案例:自己推特账号被黑经历,“受害者”现身说法。
53:32 Ilya:“if you value intelligence above all other human qualities, you’re gonna have a bad time.”
附录:
Allen AI(Allen Institute for AI):已故微软联合创始人、慈善家保罗・艾伦于 2014 年创立的非盈利研究机构
Eleuther:一个草根、非盈利 AI 研究机构
FlashAttention:基于分块计算的注意力优化技术,减少内存占用并提升效率
MLA:多头潜在注意力机制,优化长序列处理效率
vLLM:大语言模型推理框架,优化显存管理和吞吐量
SGLang:结构化生成框架,支持灵活域特定语言控制
ESFT(Expert Specialized Fine-Tuning):专家特化微调技术
NPU:神经网络处理器(一种 AI 芯片),专为深度学习计算优化能效
FP8:混合精度计算格式,平衡性能与数值稳定性
☆《晚点聊 LateTalk》建立「 播客听友群」啦!☆
欢迎关注科技、商业大公司动态和创业创新的小伙伴进群交流,第一时间收听新节目。
这里有更多互动,更多话题讨论。欢迎贡献选题 & 推荐嘉宾。
请先添加「晚点」小助手的微信号,备注:“晚点聊”,我们邀请您入群。

相关链接
光年之外联创再出发,与袁进辉聊 AI Infra 到底做什么?
DeepSeek Inside:彻底的技术开放,成就的商业奇观
本期主播:小红书 @曼祺_火柴Q,即刻 @曼祺_火柴Q

☆《晚点聊 LateTalk》建立「 播客听友群」啦!☆
欢迎关注科技、商业大公司动态和创业创新的小伙伴进群交流,第一时间收听新节目。
这里有更多互动,更多话题讨论。欢迎贡献选题 & 推荐嘉宾。
请先添加「晚点」小助手的微信号,备注:“晚点聊”,我们邀请您入群。

关注公众号《晚点 LatePost》和《晚点对话》,阅读更多商业、科技文章:

 Stay Connected
Stay Connected